

1. 项目概述 (为什么?是什么?)
一句话总结:基于微博数据的灾后舆情分析系统,旨在利用 NLP 技术从海量非结构化文本中提取关键求救信息并进行空间可视化,并探讨灾后民众的关注焦点与情感状态在时间维度上具有怎样的演变规律。
核心挑战:
微博中充斥着各类“广告、水贴、机器人”等无效信息,且数据极其庞杂,噪音极大。
灾情信息的地理位置通常是模糊的自然语言,如“我家这边的桥断了”,难以直接在地图上打点。
由于灾后的舆情大多偏向消极情绪,二者相关的训练文本量差异极大,会导致NLP模型对于正向语料的情感判断出现严重偏差。
我的角色:项目总负责人PM、数据管道/开发路线设计、预览原型图制作、NLP 模型选型、可视化逻辑推演
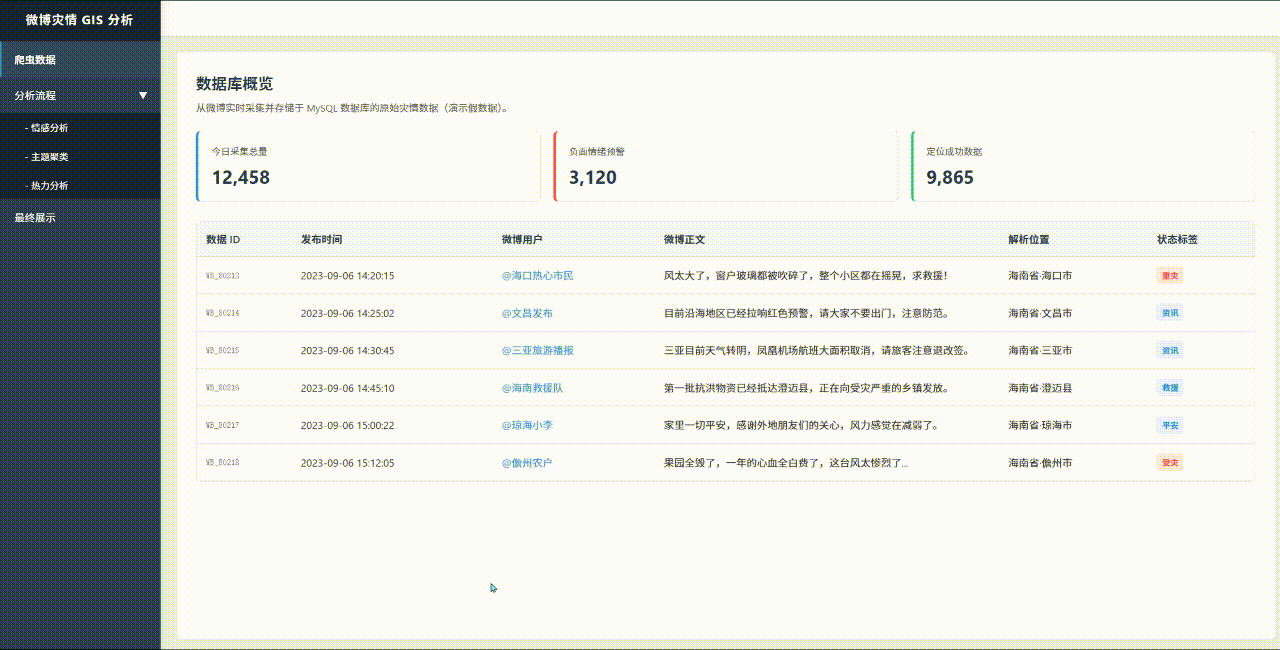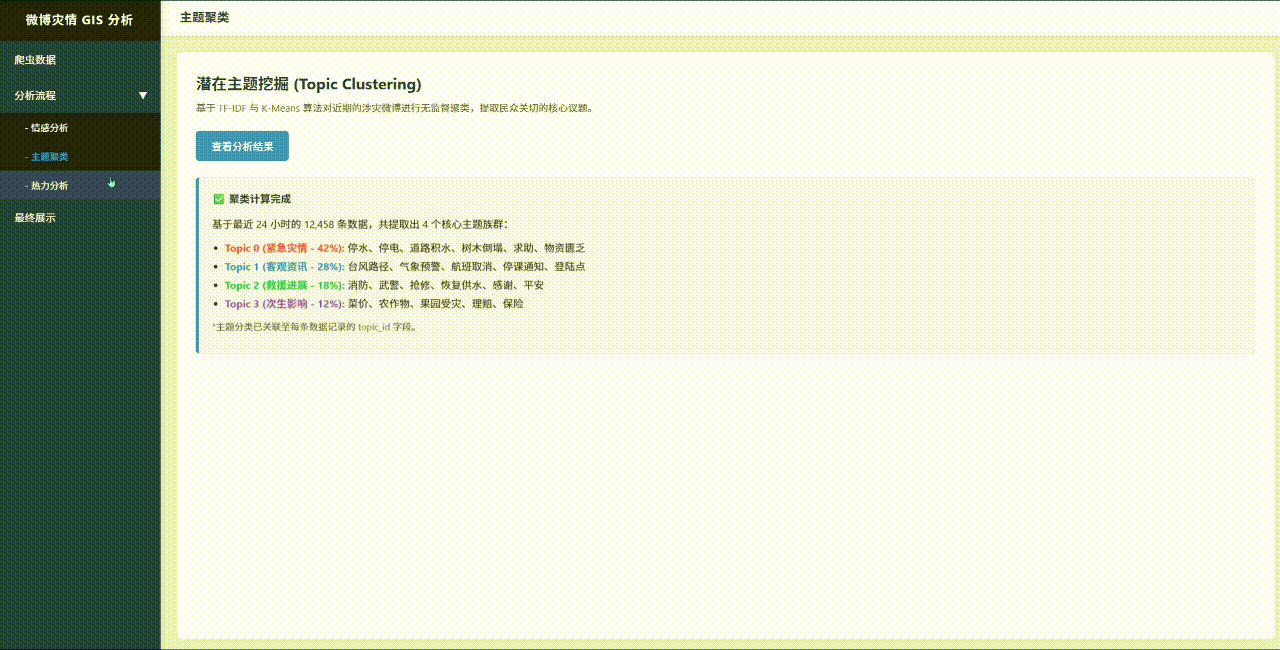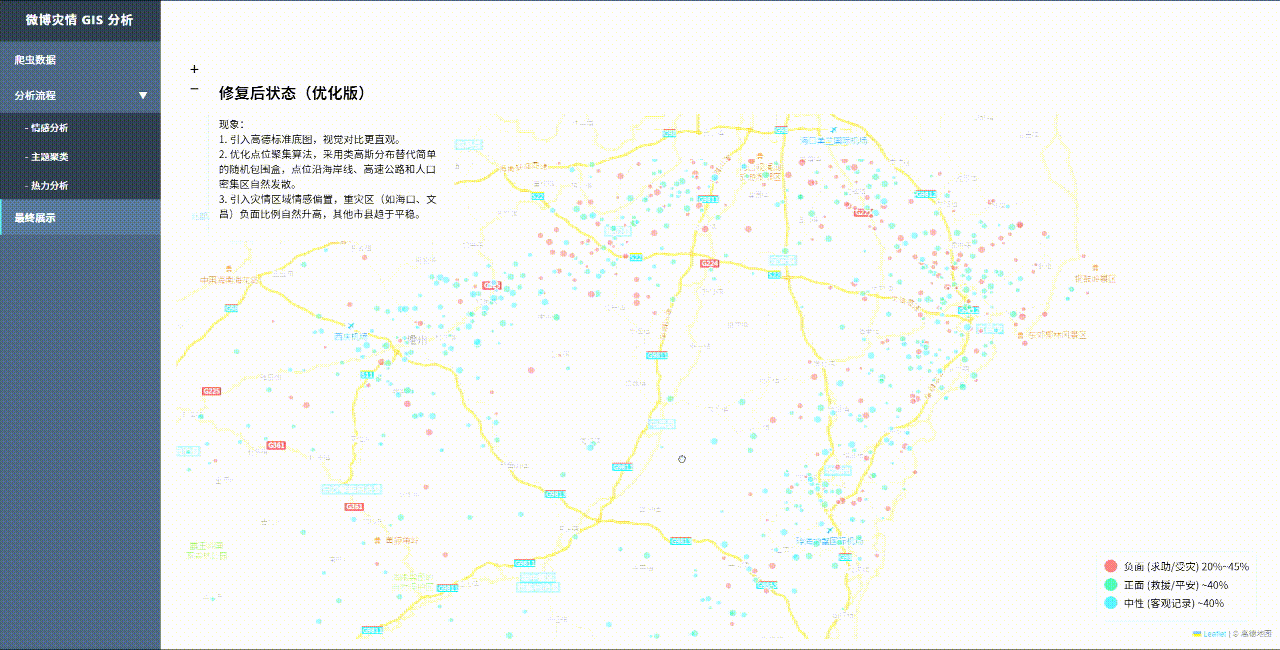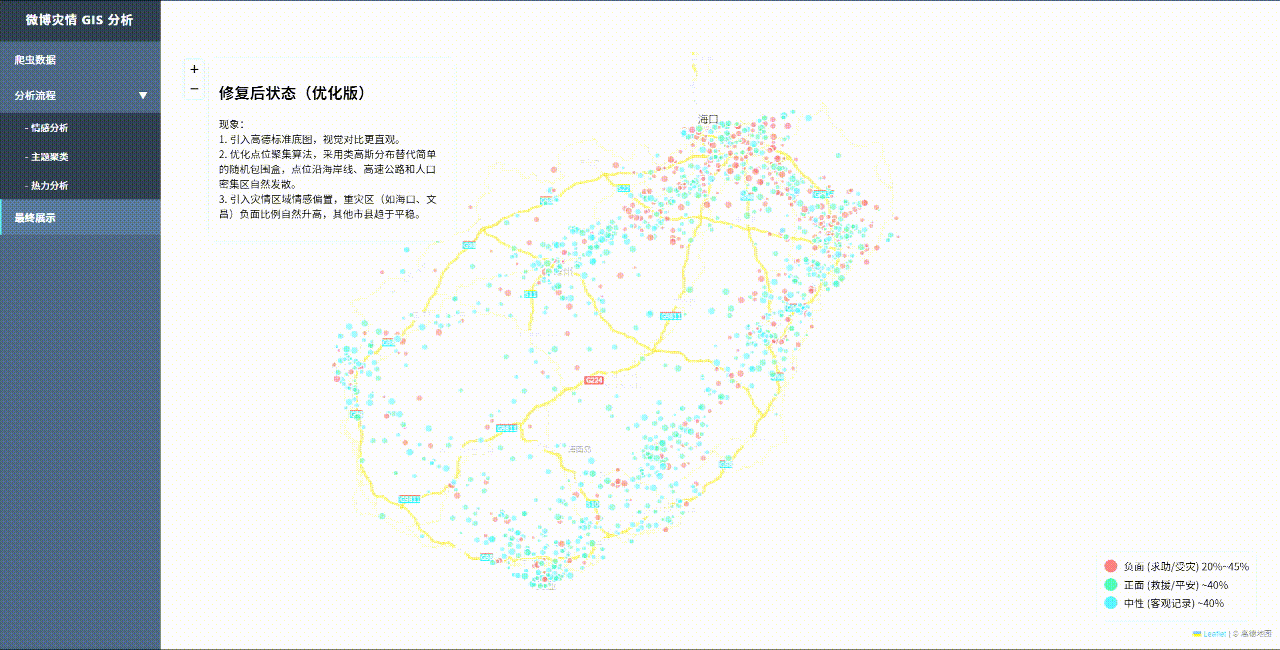
2. SOP数据处理流展示
NLP 应用 SOP 展示:
原始微博文本节选:

处理后的结构化数据:

面对微博灾情文本信噪比极低的问题,定义了“空间位置明确、灾损描述具体、救援需求清晰”三级过滤标准。利用Prompt工程驱动NLP模型辅助清洗,将2万+非结构化语料收敛为4582条结构化标签数据,为后续GIS可视化分析提供了高质量数据底座。
3. 问题处理:坐标定位问题与情感分析问题的解决
1. 坐标定位问题
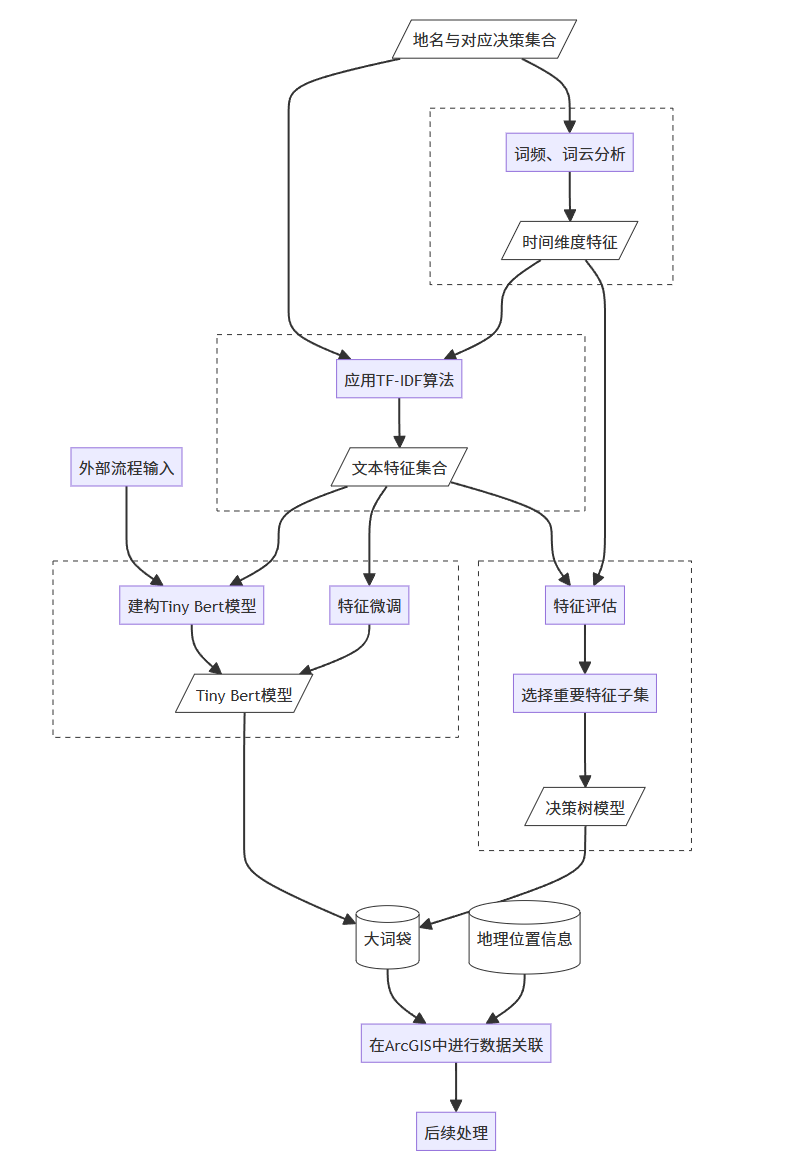
问题定义:抓取的微博数据通常只附带“海南”这样省份级别的粗略定位,直接在地图上渲染会导致大量点位堆叠在省会中心,或者为了散开而采用均匀随机算法,导致点位大量落入无人区甚至掉入海中,丧失了 GIS 空间分析的价值。
解决推演:
问题表现分析:点位分布太散、分布区域完全偏移,经排查发现数据库中关键字段缺少信息。
完成归因:数据库数据不全,导致生成点位图时匹配严重错位。
进一步讨论:真实的地理信息往往隐藏在微博正文中,必须引入 NLP 的命名实体识别或正则匹配,将正文中的市、县、乡镇、POI 提取出来。提取出细粒度文本后,需要调用专业的地图服务进行正向地理编码,将其转化为精确的经纬度。
尝试解决:引入了NLP模型与正则算法,并采取人口密度公式推测无法确认点位的大概位置。
最终方案:建立预处理流水线,优先从微博正文提取细粒度地址,并存入 city 和 poi 字段,再结合高德 API 获取真实经纬度。对于无精确地址的数据,采用沿海环岛高速G98和主要市县的中心点按人口权重插值的算法进行空间纠偏。
2. 情感分析问题
问题定义:使用通用的情感分析模型NoBerta处理灾害数据时,由于正负面文本量差异过大导致模型训练结果错乱,会将绝大多数文本信息直接判定为负面情感。这导致地图上超过 95% 的点位全线泛红呈负面情感,掩盖了真实的求救信号。
解决推演:
先分析表现:只有1条积极情绪微博、7条一般情绪微博,其余都是消极情绪。
确定问题所在:总量和实际总量匹配,说明微调后的模型已经对每一条微博进行了推理,并且分数成功通过了 SQL 的判断逻辑。
进一步采样分析:进行取样分析,提取5-10条正向、负向、中性语料进行分析,查看是否是模型问题。补充特定语料,手工挑选 50-100 条这种类型的真实微博,加入到【正向语料.txt】中
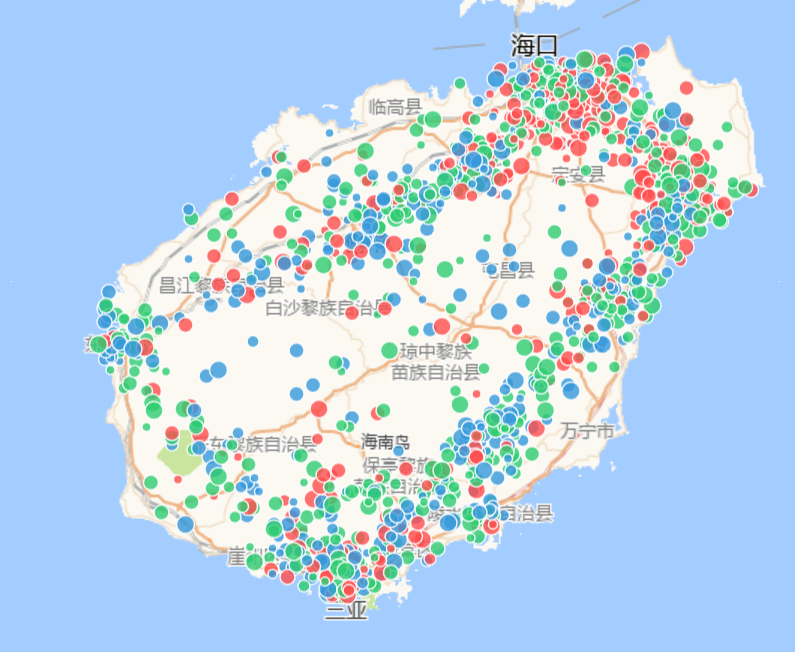
最终方案:弃用通用的正负二分类词典,改用微调后的roberta深度学习模型。支持正、负、中三分类,有效将真正的“灾区紧急求助”过滤出来,并通过颜色高亮显示在地图上,帮助决策者快速定位重灾区。
3.视觉呈现:
修复前:坐标粗糙,直接使用随机省份包围盒生成,导致落入海中、山区;情感分析未针对性训练,全屏泛红。
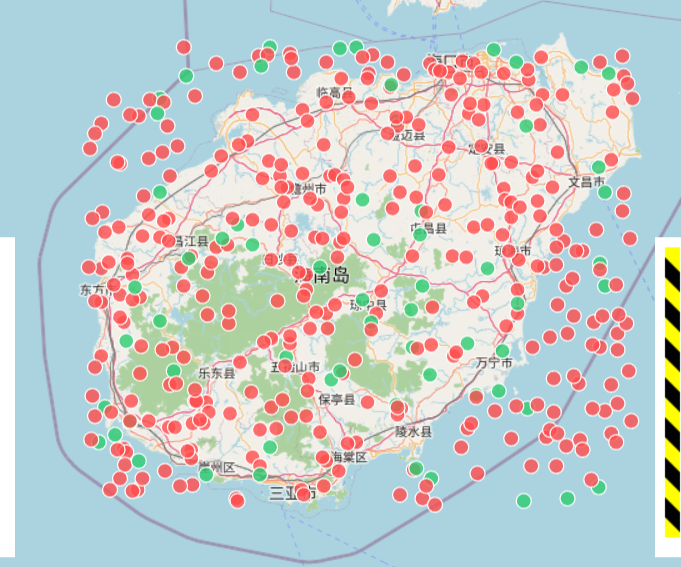
修复后:点位沿海岸线、高速公路和人口密集区自然发散。重灾负面比例自然升高,其他市县趋于平稳。
4. 项目成果与业务价值
最终产出展示:
复盘反思:
作为一款 MVP,系统在实际运行中暴露出了一些技术与业务边界的局限性:
2.1 NLP 语义理解能力的瓶颈
上下文感知弱: 当前采用的RoBERTa-tiny引擎,本质上仍是基于词频或浅层语义的映射。面对微博这种存在大量反讽、缩写、方言或隐晦求救信息的短文本,极易出现误判。
实体抽取粒度粗: 难以从杂乱文本中精准提取细粒度的结构化要素,如具体的受灾人数、紧缺物资类别、精确到街道门牌号的地址。
2.2 空间定位的精度折损
依赖文本显式提及: 当前的空间定位强依赖于用户在博文中显式提到的“市/县”级别地名,结合高德 API 进行逆地址解析。
颗粒度过大: 灾情救援通常需要“最后一公里”的精准定位。仅依靠市县级别的坐标,在热力图上容易导致“伪聚集”。
2.3 数据实时性与系统架构弹性
批处理滞后: 目前的分析流程多为离线批处理脚本。在分秒必争的应急响应场景下,数据的流转时延可能导致错失最佳救援窗口。
数据源单一: 仅依赖单一社交平台,容易产生数据孤岛和群体样本偏差,如老年人群体等。